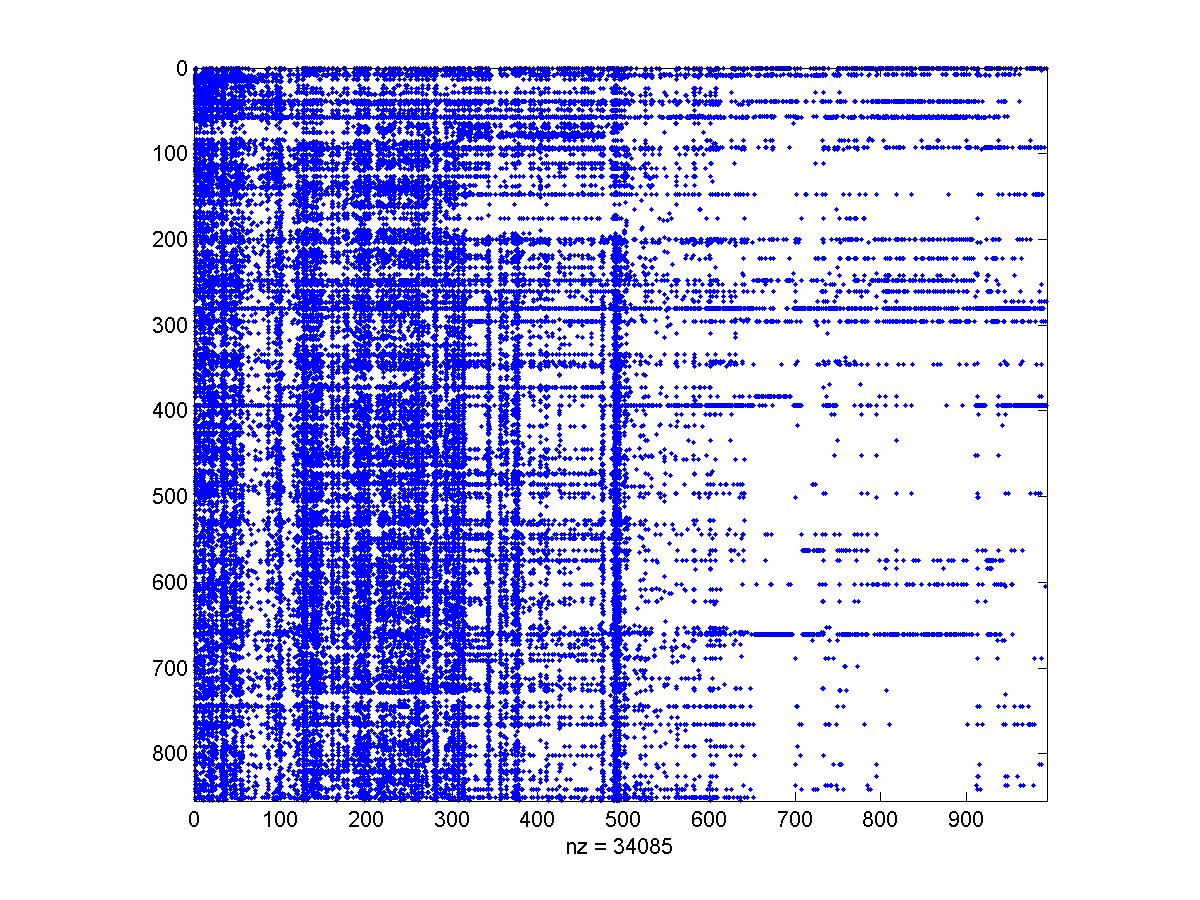
Using the spy command and the sparse matrix output from eachMovieFileReader.m it is possible to visualize the missing information pattern across the users. The following image shows a blue dote when the appropriate user (row) reported a preference on the appropriate item (column). The rows represent the first 600 users and the column the items that the first 600 users reported their preferences.
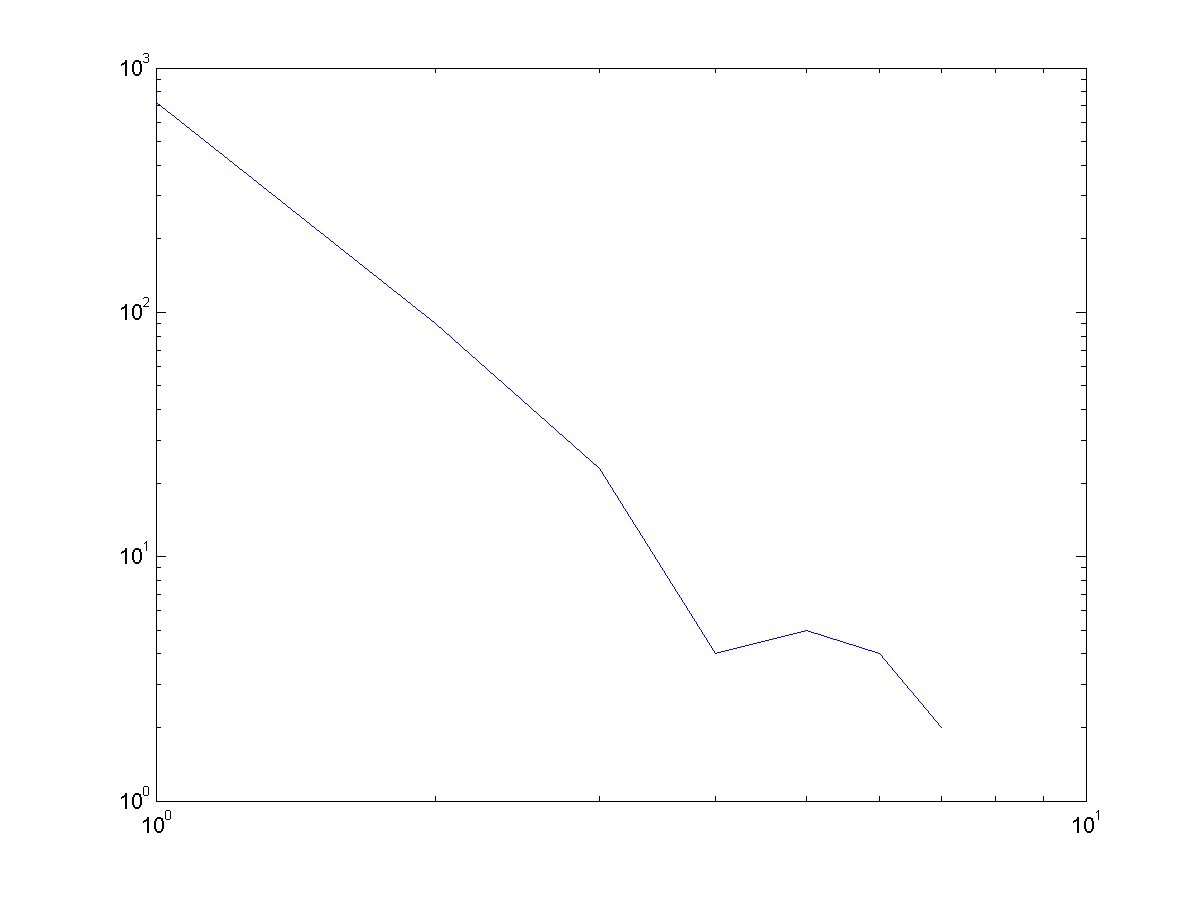
Power law behavior of the number of users reporting preference of each item and the number of items each user reports
The histogram of the number of users reporting the preference of the different items exhibit a linear trend in the log-log scale. The x axis represent how times items were reported and the y axis represent number of items that fall in this category. 10 bins were used in generating the histogram.

The histogram of the number of items the different users report exhibit a linear trend in the log-log scale. The x axis represents number of users reporting the same items and the y axis representing number of occurrences that fall in this category. 10 bins were used in generating the histogram.
Rank-Value plots
The following two graphs show rank-value graphs for the number of votes the different items have (first figure) and the number of items different users report.

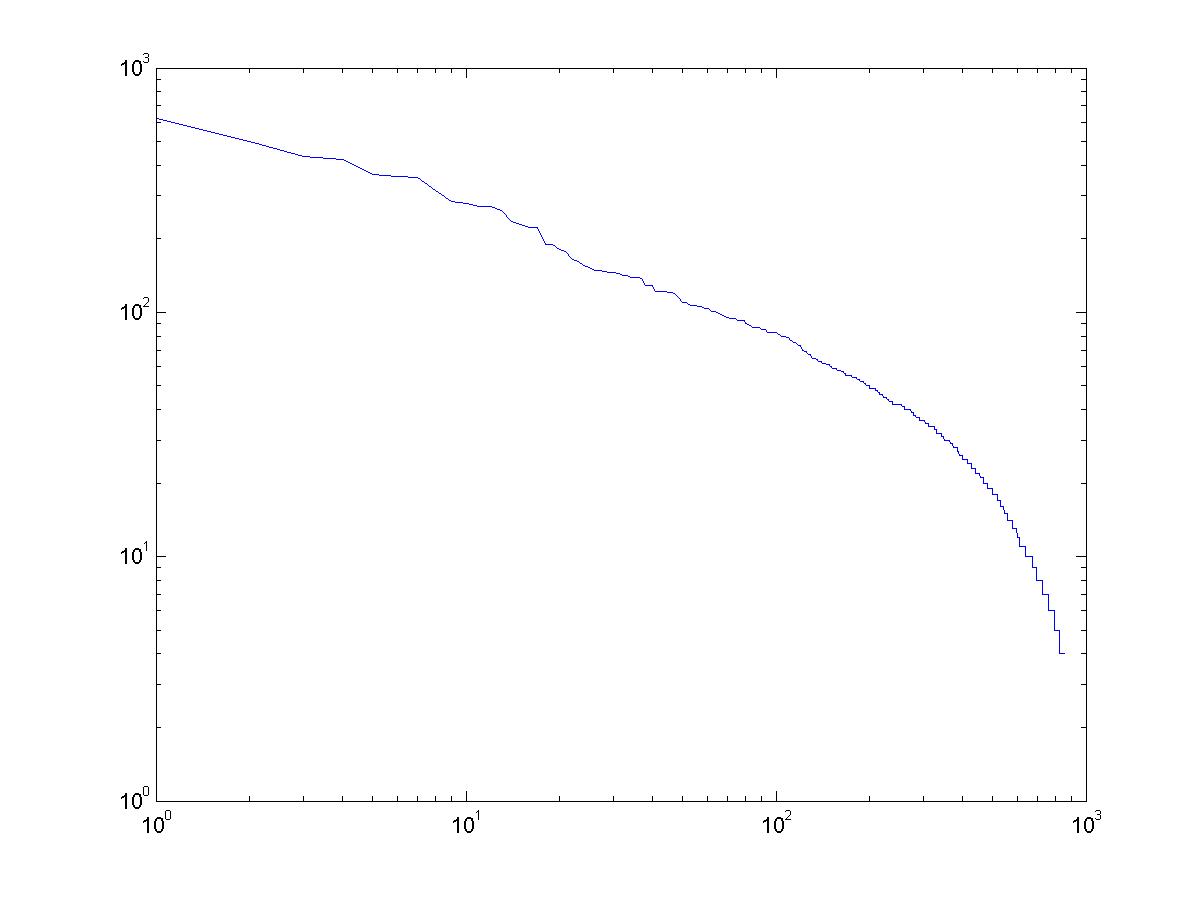
statistics for the graphs above were obtained from analyzing the first 1000 users.
Performance comparison of different collaborative filtering strategies
We compared the performance of three different CF systems: Pearson correlation coefficient, vector similarity and personality diagnosis (using standard deviation parameter of 0.7). An additional baseline of predicting a average performance for all items was also considered. The evaluation measures are mean absolute deviation, mean square error and ranked evaluation measure which measures the expected true preference of the chosen item when the probability to choose a recommended item decays exponentially with its location in a sorted list of recommendations. This is a generalization of the measure in Heckerman et al., 2000 for multiple preference values.
| Pearson correlation | vector similarity | personality diagnosis | constant mean value recommendation | |
| mean absolute deviation (lower=better) |
1.0243 | 1.0090 | 1.1863 | 1.4738 |
| mean square error (lower=better) |
1.7664 | 1.7219 | 2.0185 | 2.7849 |
| ranked evaluation (higher=better) |
4.8426 | 4.8254 | 4.7676 | 4.3562 |
The experiments performed showed that Pearson correlation performed almost as well as vector similarity but personality diagnosis lags somewhat behind (yet still outperforms the trivial recommender of mean preference). Personality diagnosis has a free parameter - the standard deviation of the Gaussian model - whose optimization may improve the model's performance.