| MT system |
Strategy1 |
Restrict2 |
Partial3 |
Anaphor4 |
Corefer5 |
Zero6 |
| Systran |
Direct |
No |
Yes |
Yes |
No |
Yes |
| Météo |
Direct |
Yes |
No |
No |
No |
No |
| SUSY |
Transfer |
No |
No |
Yes |
No |
No |
| Ariane |
Transfer |
No |
No |
Yes |
No |
Yes |
| Eurotra |
Transfer |
No |
No |
No |
No |
No |
| METAL |
Transfer |
No |
Yes |
Yes |
No |
Yes |
| Candide |
Transfer |
Yes |
No |
No |
No |
No |
| Inter-Nostrum |
Transfer |
Yes |
Yes |
No |
No |
No |
| IXA |
Transfer |
No |
Yes |
No |
No |
No |
| Episteme |
Transfer |
No |
No |
No |
No |
No |
| KANT |
Interlingua |
Yes |
No |
Yes |
No |
Yes |
| DLT |
Interlingua |
No |
No |
No |
No |
No |
| DLT (BKB) |
Interlingua |
No |
No |
Yes |
No |
No |
| Rosetta |
Interlingua |
No |
No |
No |
No |
No |
| CREST |
Interlingua |
Yes |
No |
Yes |
Yes |
Yes |
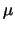 kosmos kosmos |
Interlingua |
Yes |
No |
No |
No |
No |
|
- 1 Strategy
of translation: direct, transfer, or interlingua.
- 2 Restricted domain.
- 3 Partial
parsing.
- 4 Resolution of intersentential
anaphora.
- 5 Identification of co-reference
chains.
- 6 Translation of zero pronouns into the target language.
|
|