

Next: Comparisons using English
Up: Evaluation of WOLFIE
Previous: Evaluation of WOLFIE
A Database Query Application
This section describes our experimental results on a database query
application. The first corpus discussed contains 250 questions about
U.S. geography, paired with their Prolog query to extract the answer
to the question from a database. This domain was originally chosen
due to the availability of a hand-built natural language interface,
GEOBASE, to a database containing about 800 facts. GEOBASE was
supplied with Turbo Prolog 2.0 [Borland International1988], and designed
specifically for this domain. The questions in the corpus were
collected by asking undergraduate students to generate English
questions for this database, though they were given only cursory
knowledge of the database without being given a chance to use it.
To broaden the test, we had the same 250
sentences translated into Spanish, Turkish, and Japanese. The
Japanese translations are in word-segmented Roman orthography.
Translated questions were paired with the appropriate logical queries
from the English corpus.
To evaluate the learned lexicons, we measured their utility as
background knowledge for CHILL. This is performed by choosing a
random set of 25 test examples and then learning lexicons and parsers
from increasingly larger subsets of the remaining 225 examples
(increasing by 50 examples each time). After training, the test
examples are parsed using the learned parser. We then submit the
resulting queries to the database, compare the answers to those
generated by submitting the correct representation to the database,
and record the percentage of correct (matching) answers. By using the
difficult ``gold standard'' of retrieving a correct answer, we avoid
measures of partial accuracy that we believe do not adequately
measure final utility.
We repeated this process for ten different random training and test
sets and evaluated performance differences using a two-tailed, paired
t-test with a significance level of
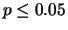 .
We compared our system to an incremental (on-line) lexicon learner
developed by Siskind (1996).
To make a more equitable
comparison to our batch algorithm, we ran his in a ``simulated'' batch
mode, by repeatedly presenting the corpus 500 times, analogous to
running 500 epochs to train a neural network. While this does not
actually add new kinds of data over which to learn, it allows his
algorithm to perform inter-sentential inference in both directions
over the corpus instead of just one. Our point here is to compare
accuracy over the same size training corpus, a metric not optimized
for by Siskind. We are not worried about the difference in execution
time here,10 and the lexicons learned when
running Siskind's system in incremental mode (presenting the corpus a
single time) resulted in substantially lower performance in
preliminary experiments with this data. We also removed WOLFIE's
ability to learn phrases of more than one word, since the current
version of Siskind's system does not have this ability. Finally, we made
comparisons to the parsers learned by CHILL when using a hand-coded
lexicon as background knowledge.
In this and similar applications, there are many terms, such as state
and city names, whose meanings can be automatically extracted from the
database. Therefore, all tests below were run with such names given
to the learner as an initial lexicon; this is helpful but not
required.
Section 5.2 gives results for a different task
with no such initial lexicon.
However, unless otherwise noted, for all tests within this Section
(5.1) we did not strip sentences of phrases known to have
empty meanings, unlike in the example of Section 4.
.
We compared our system to an incremental (on-line) lexicon learner
developed by Siskind (1996).
To make a more equitable
comparison to our batch algorithm, we ran his in a ``simulated'' batch
mode, by repeatedly presenting the corpus 500 times, analogous to
running 500 epochs to train a neural network. While this does not
actually add new kinds of data over which to learn, it allows his
algorithm to perform inter-sentential inference in both directions
over the corpus instead of just one. Our point here is to compare
accuracy over the same size training corpus, a metric not optimized
for by Siskind. We are not worried about the difference in execution
time here,10 and the lexicons learned when
running Siskind's system in incremental mode (presenting the corpus a
single time) resulted in substantially lower performance in
preliminary experiments with this data. We also removed WOLFIE's
ability to learn phrases of more than one word, since the current
version of Siskind's system does not have this ability. Finally, we made
comparisons to the parsers learned by CHILL when using a hand-coded
lexicon as background knowledge.
In this and similar applications, there are many terms, such as state
and city names, whose meanings can be automatically extracted from the
database. Therefore, all tests below were run with such names given
to the learner as an initial lexicon; this is helpful but not
required.
Section 5.2 gives results for a different task
with no such initial lexicon.
However, unless otherwise noted, for all tests within this Section
(5.1) we did not strip sentences of phrases known to have
empty meanings, unlike in the example of Section 4.
Next: Comparisons using English
Up: Evaluation of WOLFIE
Previous: Evaluation of WOLFIE
Cindi Thompson
2003-01-02